OhMyGraphs: Graph Attention Networks
This post follows from the intuition and notation in the GraphSAGE post in this series; check it out to follow along better! On the heels of GraphSAGE, Graph Attention Networks (GATs) [1] were proposed with an intuitive extension — incorporate attention into the aggregation and update steps.
What are Graph Attention Networks?
GATs are an improvement to the neighbourhood aggregation technique proposed in GraphSAGE. It can be trained the same way as GraphSAGE to obtain node embeddings, but there is one extra step involved. This extra step is intended to compute attention coefficients which signify how important one node is to another node’s representation.
The main idea behind GATs:
Pay attention to those that matter.
In the previous post, we tried to guesstimate who the middle node could be, based on the neighbouring nodes. If you guessed Scooby Doo, it’s because you looked at the meddling kids and realized whoever was in the middle, had to have a relationship with all the other nodes.

But, were each of the characters equally important in you deciding the middle node was Scooby Doo? Arguably, you may have guessed Scooby Doo just from seeing the Shaggy node. Observing Velma and Daphne were probably a little bit important and its likely that Fred being there didn’t really help you guess who was in the middle.

If you guessed Scooby Doo based on placing different importance levels on Fred, Velma, Daphne and Shaggy, then you’ve just successfully performed graph attention in your head!
Notation for GAT:
Recall, every node can have their own feature vector which is parameterized by X. Typically, the shape of X, for every node, is (F,1) where F is the number of features each node contains. Let’s assume for now that all nodes have the same number of features F.
Similar to GraphSAGE, the goal of GAT is also to learn a representation for every target node based on some combination of its neighbouring nodes. This node representation is typically parametrized by h which has a shape of (F’,1) where F’ is the number of embedded features. Also, F’<< F.

Different from GraphSAGE, the authors propose that the GAT layer only focus on obtaining a node representation based on the immediate neighbours of the target node. That means, k=1 because we are only focusing on the first neighbourhood or first hop. However, GAT can be performed with k>1 — it just might be computationally costly but comparable to running GCN [1].
GAT Overview
The GAT layer follows a 3 step process. It looks at the immediate neighbours of a target node, and computes the target node embedding based using an aggregation and update function. The meatiest part of the GAT layer is actually in computing the attention coefficients depicted in green below:

1. Compute attention coefficients
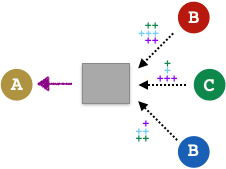
In the figure above, the alpha values signify the importance of neighbouring nodes on the target node. For example:
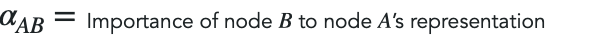
Calculating this attention scalar is a 4 step process depicted below:
1a. Transform each node embedding vector
- This is a shared, linear transformation where the matrix W has shape (F’, F). It’s called shared because every node is transformed by this W matrix.
- The goal of this step is to transform the node features from a dimensionality of F, to a common dimensionality of F’. This step is repeated for all the nodes in node i’s neighbourhood, including node i
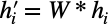
1b. Compute intermediate attention scalars e_ij
- This step concatenates the target node i’s embedding representation h_i with all its possible neighbours in its immediate neighbourhood.
- Each pair is then concatenated and transformed by matrix W^a which has shape (2F’,F’). The output dimension F’ may have the same dimensionality as in step 1a or it could be different — it is a hyperparameter.
- The goal of this step is to perform shared attention learning between node pairs, disregarding actual graph structure.
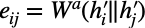
- In the paper, W^a is called a single layer neural network. I am omitting the bias term to minimize equation clutter. Note, W^a can be replaced by something non-learnable, like simple averaging.
1c. Normalize intermediate attention scalars
- This step activates each of the intermediate attention scalars by a non-linear activation, denoted by the \sigma.
- In the GAT paper, the authors use LeakyReLU as the non-linear activation function.
- Lastly, the activated intermediate attention scalars are passed through a softmax layer which turns the attention coefficients into a probability distribution.
- The goal of this step is to normalize attention coefficients such that the attention coefficients a_ij add up to 1.
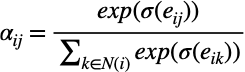
1d. Repeat for m attention coefficients
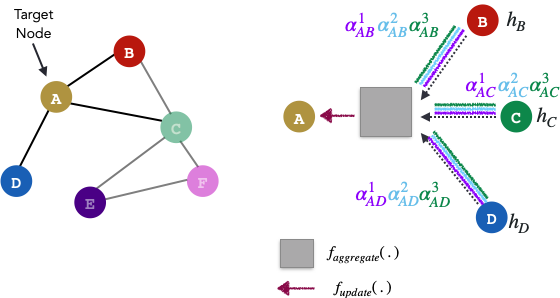
- In the spirit of deep learning, the GAT authors propose to compute multiple attention coefficients between the target node and its neighbouring nodes, as depicted above.
- This is done by repeating steps 1a, 1b and 1c for m number of times. In the paper, the GAT authors set m=3.
- The goal is to extend the expressivity of the network to capture different importances to nodes of a similar neighbourhood.
Phew, if you got up to here, the hard part is done! Now with various attention coefficients computed, we can perform the neighbourhood aggregation!
2. Aggregate
The GAT aggregation step is a linear aggregation, scaled by the attention coefficients.
- The authors propose that the f_aggregate function to be a linear transformation — therefore the node embedding vector of all the neighbours of the target node and the target node itself, node i are transformed by weight matrix W.
- This linear transformation is scaled by the attention coefficient \alpha_ij and lastly transformed by a non-linear activation function denoted by \sigma. This forms the aggregated vector representation for node i, denoted by a_i.
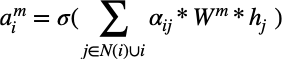
- Recall, since we have m attention coefficients, we must do the aggregation step m times such that we have m number of a_i’s.
- There is a separate weight matrix W^m for each attention head so that the head can learn different levels of importance to the same neighbourhood nodes.
- The aggregated node representation will have dimensionality (F,1).
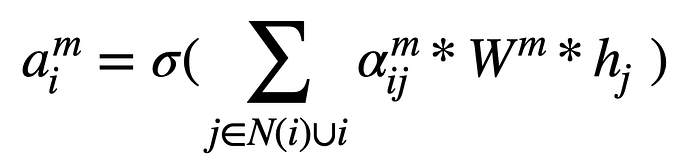
3. Update
After aggregating node representations, the last step is to update the target node representation. The authors propose two different ways of updating the final node embedding representation for node i after one round of GAT:
3a. Concatenation
- For GAT layers that are not the final layer in the network, the authors propose the f_update function to be the concatenation operator.
- This update will concatenate the m-aggregated representations in the feature dimension.
- The final node representation for target node i, h_i, will have dimensionality (m*F’, 1).
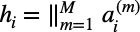
3b. Averaging
- For GAT layers that are the final layer in the network, for example, the final classification layer, the authors use the propose the f_update function to be the mean operator to aggregate the m-representations.
- This is done because if we’re at the last layer, the number of output features F’ would correspond to the number of classes we are classifying, and concatenation would not make sense because it would increase the dimensionality.
- The final node representation in the averaging case will have dimensionality (F’, 1).
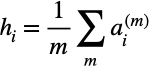
Was all this worth it?
The performance of GAT on supervised, inductive tasks is actually quite impressive when compared to its GraphSAGE counter parts. Below observe one of the inductive tests on the Protein-Protein-Interaction dataset:
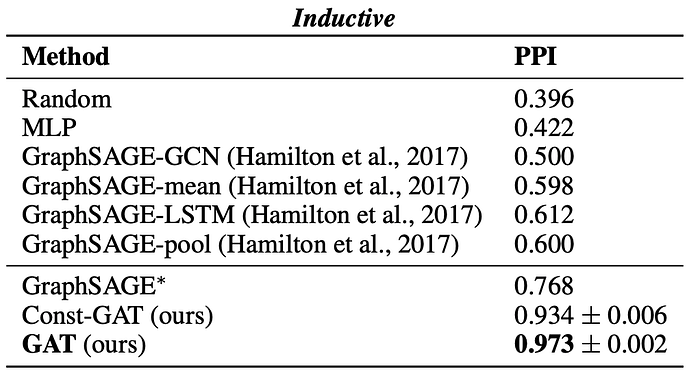
Where the following models are defined as:
- MLP = treating all the nodes as independent features, without any graphical structure
- GraphSAGE-GCN/mean/LSTM/pool = GraphSAGE with different types of aggregators
- GraphSAGE* = The best GraphSAGE the GAT authors could implement
- Const-GAT = GAT where all the a_ij = 1, therefore no learnable attention coefficients are used
- GAT = Proposed 3 layer GAT
It’s interesting to note that the different between Const-GAT and GAT is only 3.9% suggesting that the actual weighting of neighbourhood nodes contributes less than the expressivity (via more parameters) of the network, as this saw almost a 20.5% boost over the best performing GraphSAGE model.
Benefits of GATs
- GATs are computationally efficient as computation over m attention heads can be done independently and is therefore parallelizable
- Attention coefficients can be visualized after training is complete to help interpret the model’s decision making
- GATs can be used in both transductive and inductive settings and at the time, outperformed existing methods in both settings
TL, DR
GAT layers perform node embedding by:
- Computing m attention coefficients
- Non-linearly aggregating feature for each m attention heads
- Updating node features by concatenation/averaging
The node embeddings have superior performance on both supervised and unsupervised tasks. For more results, check out the paper!
FYI, the number of attention coefficients m is represented by the parameter k in the actual paper. I’ve switched it to m because k is typically representative of neighbourhood hops and I didn’t want there to be any confusion :)
Code implementation coming soon!
